机器学习的应用领域广泛,其中图像处理是一个充满挑战和机遇的领域。在进行图像分类和分析时,特征提取是一个重要且必要的步骤。本文将指导你如何实现机器学习图像类型的数据特征提取及其结果分析。我们将分步进行,并提供相应的代码示例。
整体流程
在进行图像特征提取及结果分析时,我们可以按照以下流程进行:
流程步骤详解
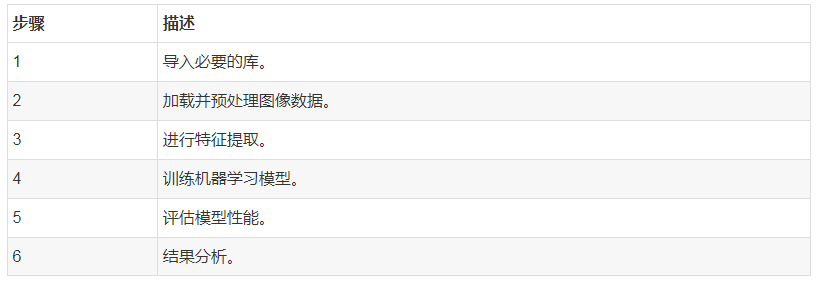
步骤详解及代码实现
1. 导入必要的库
首先,我们需要导入必要的Python库,如opencv, numpy, sklearn等。这些库将帮助我们处理图像、进行数值计算以及训练模型。
import cv2 import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report import glob
注:在代码中,我们使用了cv2来处理图像,numpy用于数组计算,sklearn提供了一系列机器学习工具。
2. 加载并预处理图像数据
我们需要加载图像数据,并进行预处理,例如调整大小、归一化等。
image_paths = glob.glob('path/to/images/*.jpg') def load_and_preprocess_images(image_paths):
images = []
for path in image_paths:
image = cv2.imread(path)
image = cv2.resize(image, (64, 64))
image = image.astype('float32') / 255.0
images.append(image)
return np.array(images)images = load_and_preprocess_images(image_paths)
注:我们读取每张图像并将其调整为统一的大小,同时将像素值归一化到0到1之间。
3. 特征提取
我们可以通过计算图像的颜色直方图作为特征,来提取图像的特征值。
def extract_features(images):
features = []
for image in images:
hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
hist = cv2.normalize(hist, hist).flatten()
features.append(hist)
return np.array(features)features = extract_features(images)
注:这里我们计算每张图像的颜色直方图,并将其归一化。
4. 训练机器学习模型
将提取的特征分成训练集和测试集,并使用RandomForestClassifier训练模型。
labels = np.array([0, 1, 0, 1]) X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)model = RandomForestClassifier(n_estimators=100)model.fit(X_train, y_train)
注:我们假设有一个项目标签,可以根据数据集调整标签的生成。同时我们用train_test_split来划分训练和测试数据。
5. 评估模型性能
对模型进行性能评估,如得到分类报告。
注:classification_report将提供模型的准确率、查全率等指标。
6. 结果分析
根据模型的输出结果,分析模型的性能,可以通过可视化的方式展示。
import matplotlib.pyplot as pltfor i in range(5):
plt.imshow(X_test[i].reshape(64, 64, 3))
plt.title(f'Predicted: {y_pred[i]}, Actual: {y_test[i]}')
plt.axis('off')
plt.show()
注:这里我们使用matplotlib来可视化测试样本及其预测标签。
