过程概要
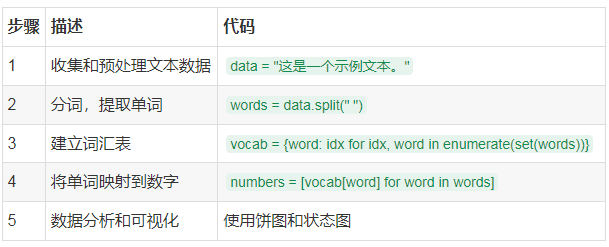
步骤详细介绍
1. 收集和预处理文本数据
这是整个流程的第一步。我们首先需要一段文本,通常来自于用户输入或数据集。
data = "这是一个示例文本。"
2. 分词,提取单词
中文的分词通常比英文复杂,因为中文是一个没有空格的语言。我们可以使用一些库(例如 jieba)来进行分词。这里是使用 split() 的示例,适用于已经预处理过的简单文本。
words = data.split(" ")
如果你使用 jieba 进行分词,可以这样实现:
import jieba
words = jieba.lcut(data)
3. 建立词汇表
词汇表是一种映射结构,存储每个单词和其对应的唯一数字。这通常通过将单词和索引结合在一起完成。
vocab = {word: idx for idx, word in enumerate(set(words))}
5. 数据分析和可视化
最后一步是对转换后的数据进行分析和可视化。我们可以用饼状图展示词汇的分布情况。
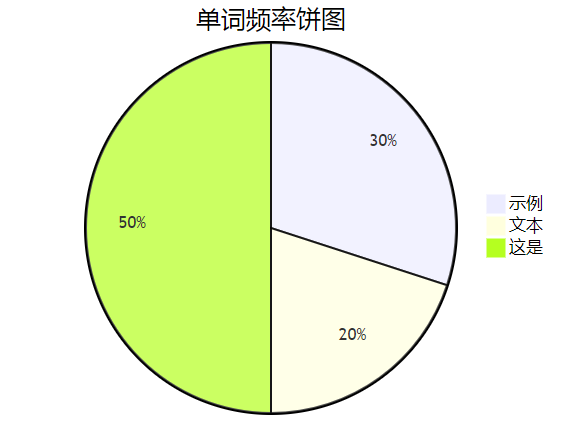
此外,我们也可以使用状态图来描述这个过程的状态转移。

