数据挖掘
数据挖掘(Data Mining)是从大量数据中提取有用信息和知识的过程。它结合了统计学、机器学习和数据库技术,能够分析大量数据并揭示潜藏的模式和关系。常见的数据挖掘技术包括聚类分析、分类、回归分析等。
示例:使用Python进行简单的数据挖掘
以下是一个使用 scikit-learn 库进行分类的数据挖掘示例:
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import accuracy_scoredata = {
'Feature1': [1, 2, 3, 4, 5],
'Feature2': [5, 4, 3, 2, 1],
'Label': [0, 0, 1, 1, 0]}df = pd.DataFrame(data)X = df[['Feature1', 'Feature2']]y = df['Label']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)classifier = DecisionTreeClassifier()classifier.fit(X_train, y_train)y_pred = classifier.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print(f'预测准确率: {accuracy:.2f}')
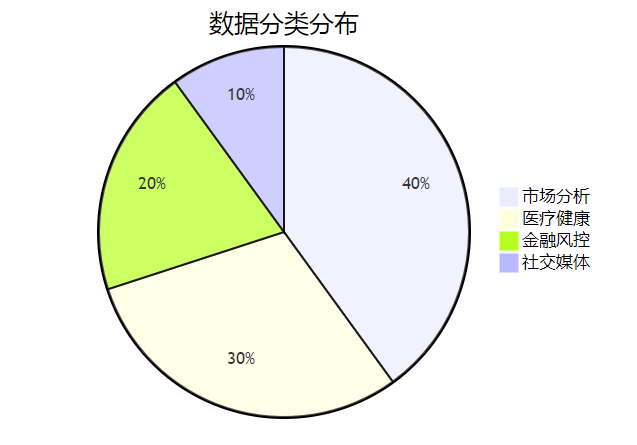
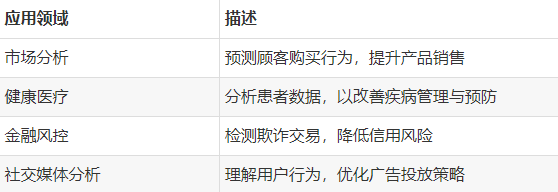
数据挖掘的应用领域
数据算法
数据算法(Data Algorithms)是指用于处理和分析数据的一系列步骤和规则。它更关注于如何高效地处理数据,而不是从中提取信息。数据算法的种类繁多,包括排序算法、搜索算法等。在机器学习中,数据算法通常指的是模型训练和优化策略。
示例:使用Python实现简单的排序算法
以下是一个冒泡排序算法的实现示例:
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arrnums = [64, 34, 25, 12, 22, 11, 90]sorted_nums = bubble_sort(nums)print(f'排序后的数组: {sorted_nums}')
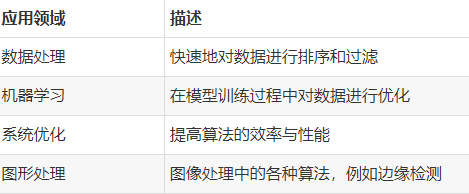
数据算法的应用领域
数据挖掘与数据算法的区别
数据挖掘和数据算法之间的主要区别可以概括为以下几点:
目的不同:数据挖掘旨在发现数据中的模式和知识,而数据算法更关注于如何有效地处理和管理数据。
技术取向不同:数据挖掘通常使用统计、机器学习等技术,而数据算法则包括更基础的计算机科学技术,如排序和搜索。
应用场景不同:数据挖掘多用于业务决策和预测分析,而数据算法则更广泛应用于各种计算任务。
总结
数据挖掘和数据算法各自扮演着重要的角色。数据挖掘帮助我们从大量数据中获取有价值的信息,而数据算法则使得这些数据的处理变得更加高效。理解这两者之间的区别,对于深入从事数据相关的工作至关重要。
为了更好地理解数据分布,以下是数据分类的饼状图: