电力负荷预测是为了通过历史数据预测短期或长期电力需求。随着智能电网的发展,数据量的爆炸式增长,采用机器学习进行电力负荷预测已逐渐成为业界的共识。我们的目标是建立一个基于机器学习的电力负荷二分类模型,以判定电力需求是否超过某一阈值,从而助力电力调度。
text{Business scale model:} quad y = f(X) \
text{where } y text{ is the load category, and } X text{ are input features such as temperature, time, and historical load.}
演进历程
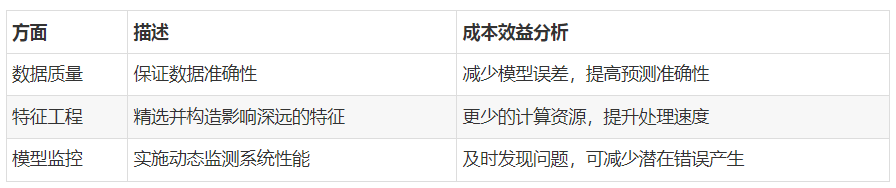
在我们的项目中,经历了多个架构迭代阶段。早期模型基于线性回归,性能有限。经过多次迭代,最终选择使用随机森林和梯度提升树等集成学习方法。
- original_features = ['temperature', 'humidity', 'time']+ improved_features = ['temperature', 'humidity', 'time', 'previous_load', 'holiday_indicator']
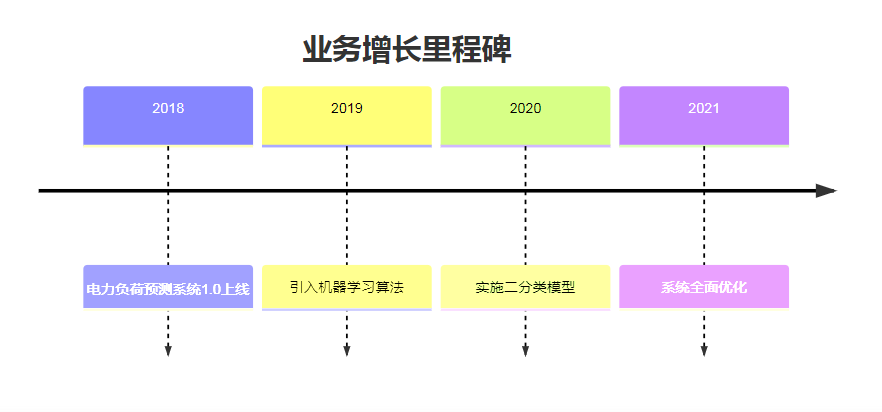
以下思维导图展示了我们的技术选型路径,从基础的统计模型到复杂的机器学习模型的演变。
架构设计
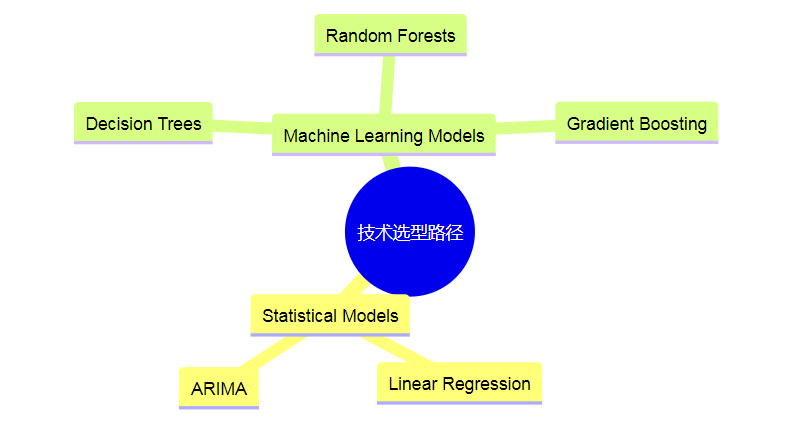
为确保系统的高可用性,设计了包含备份和负载均衡的架构。请求处理链路如下所示:
性能攻坚
在模型训练过程中,通过调整超参数和特征选择显著提升了模型性能。我们使用了多种调优策略来实现性能提升,如下所示:
sankey-beta
title 资源消耗优化对比
A[初始模型] -->|50% 计算资源| B[优化后的模型]
A[初始模型] -->|30% 内存| C[优化后的内存使用]
A[初始模型] -->|20%时间| D[优化后的时间]
故障复盘
在系统上线初期,曾遭遇重大故障,导致预测结果严重失效。故障扩散路径如下:
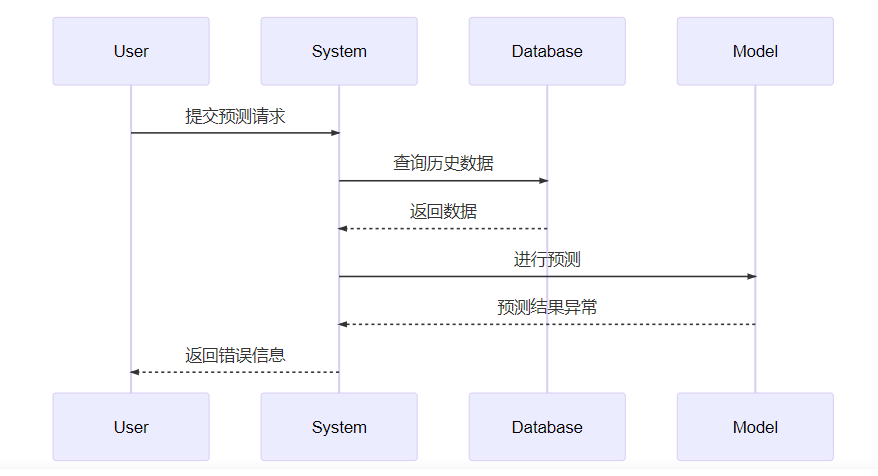
检查清单列出防御措施以避免未来类似问题的发生:
数据有效性检查
模型监控预警
定期重训练与评估
复盘总结
通过这次项目,我们总结出以下可复用的方法论: